Welcome to the homepage for our bachelor project! It is created in order to have a better medium to communicate the development of the project as well as the results generated in the processs. Every time our GIT repo is updated, this page will be updated as well with the latest visualizations and other things that we choose to show.
Webpage description
Home
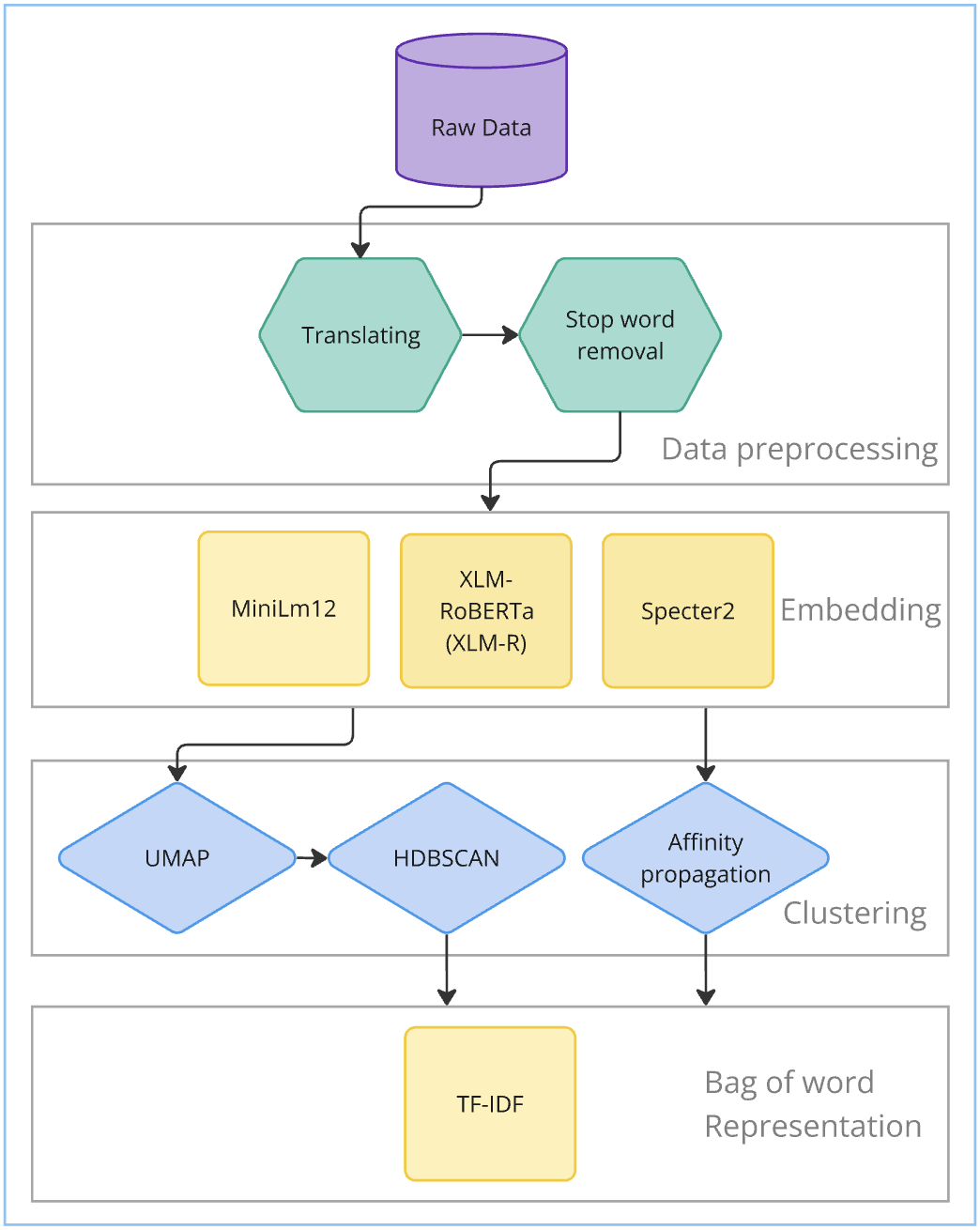
Project and pipeline description
Final results
This contains all the clusters generated by our three models, to be inspected
Final Plots
The final plots used in the thesis
Version 2 plots
The second version of plots as a part of the process
Version 1 plots
The first version of plots as a part of the process
About
Info about the team
Project Description:
This project investigates the discourse surrounding Denmark’s energy islands initiative by analyzing how the topic is discussed across scientific literature, professional media, and regional media. Using Natural Language Processing (NLP) techniques, particularly topic modeling methods such as BERTopic and Latent Dirichlet Allocation (LDA), the study aims to identify key themes, trends, and differences in how energy islands are framed in different contexts. The project contributes to the European Research Center (ERC) project Goodbye Devising, which seeks to integrate local citizen values and environmental concerns into the early stages of green energy planning. By applying NLP-based text analysis, this research provides insights for policymakers, scientists, and communicators to bridge the gap between expert knowledge and public understanding of Denmark’s energy transition.
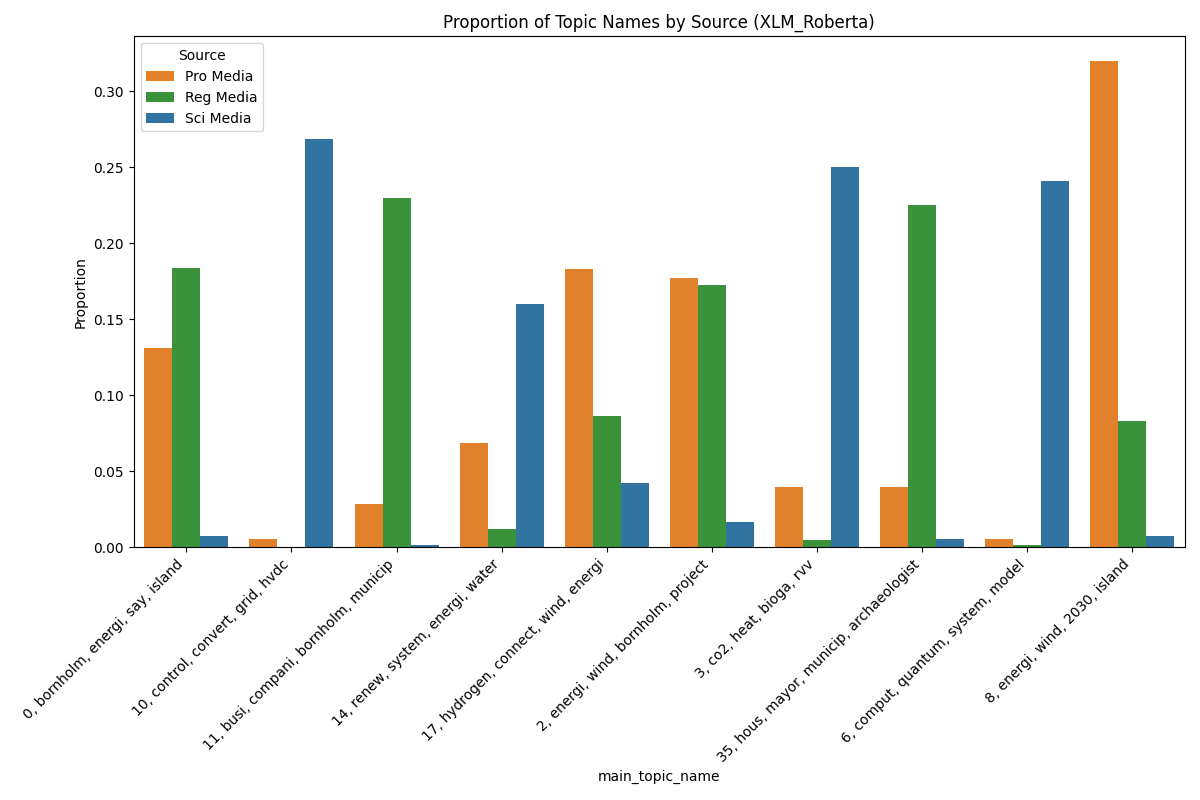
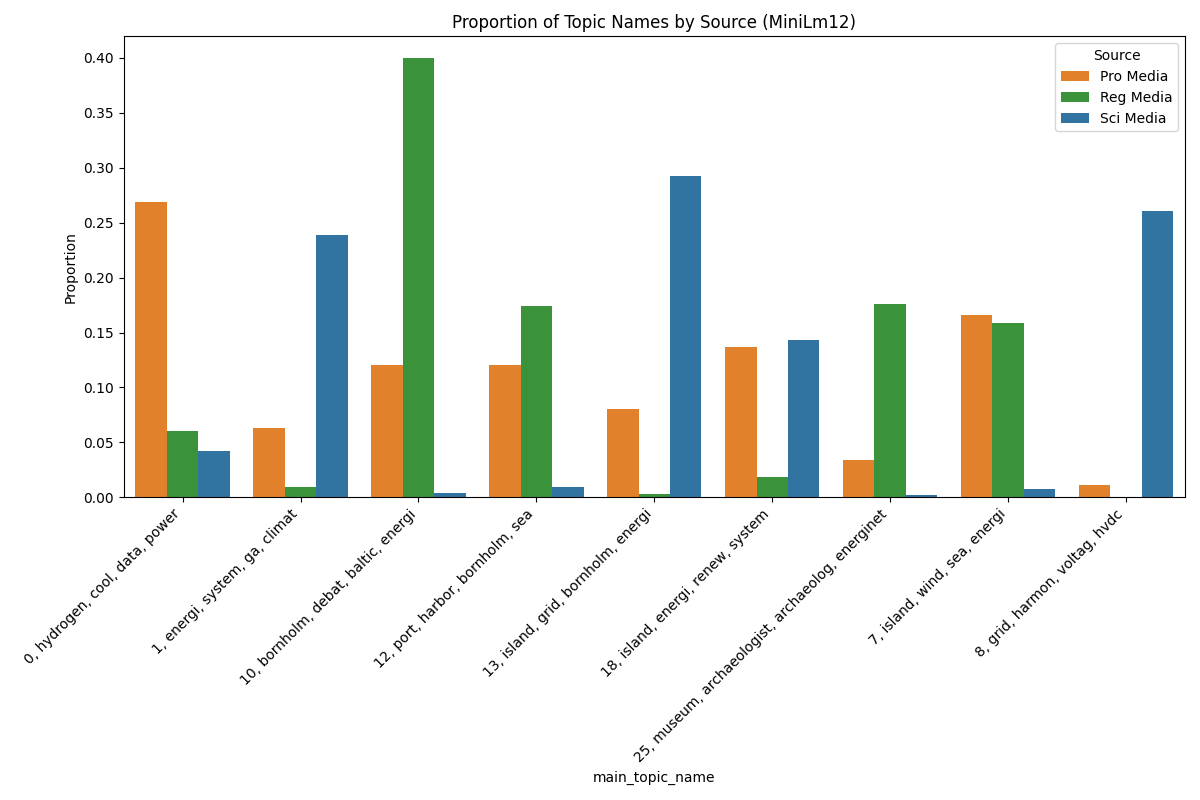
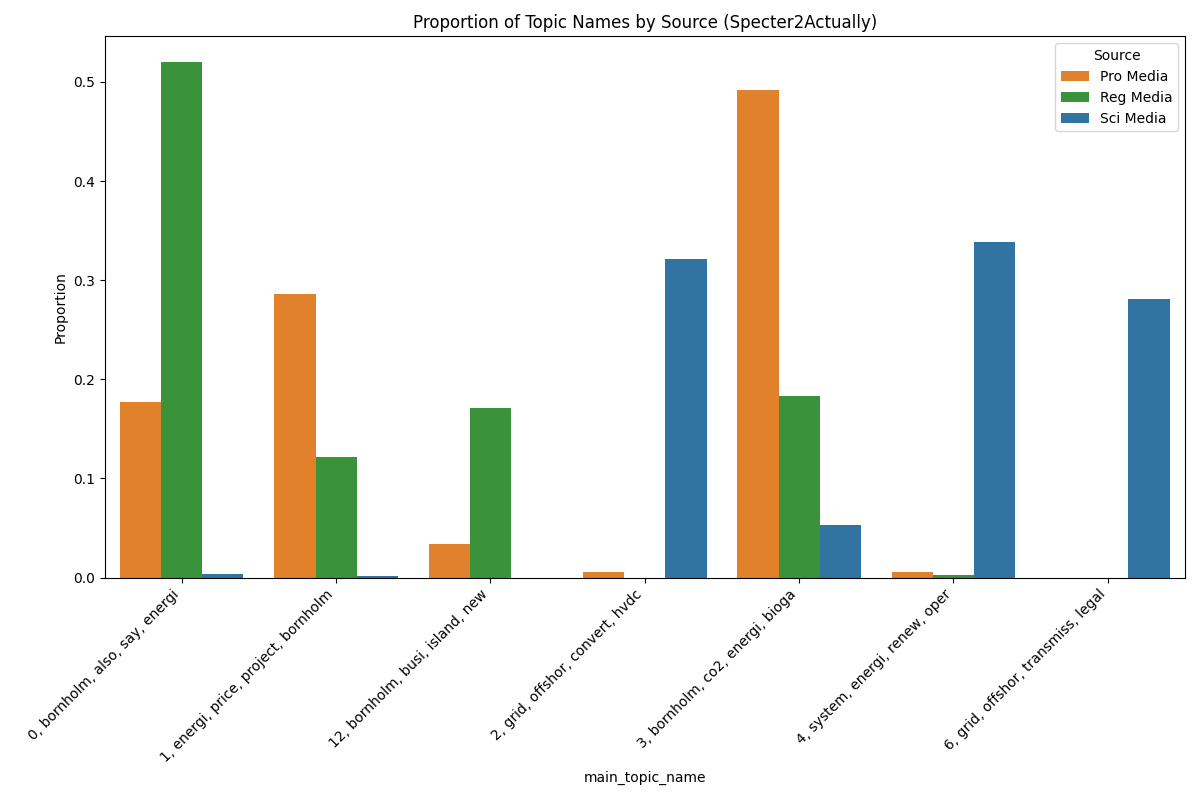
Based on our final clustering and TF-IDF cluster representation, here the results can be found. All the clusters are presented, with their BoW TF-IDF score, doc and term count.
Cluster investigation
This is a WIP and is not a part of the final handin
In order to investigate the many clusters generated, we investigated how to group the clusters with similar BoW representations. The idea was to group the clusters in order for the qualitative analysis to become easier. Many issues with the grouping was found and therefore it was abandoned since, it would take substantial time to develop. Therefore it was abandoned, and therefore what is presented is WIP.
Plots based on version 1 (old)
These are old plots from a previous version and are not a part of the final handin
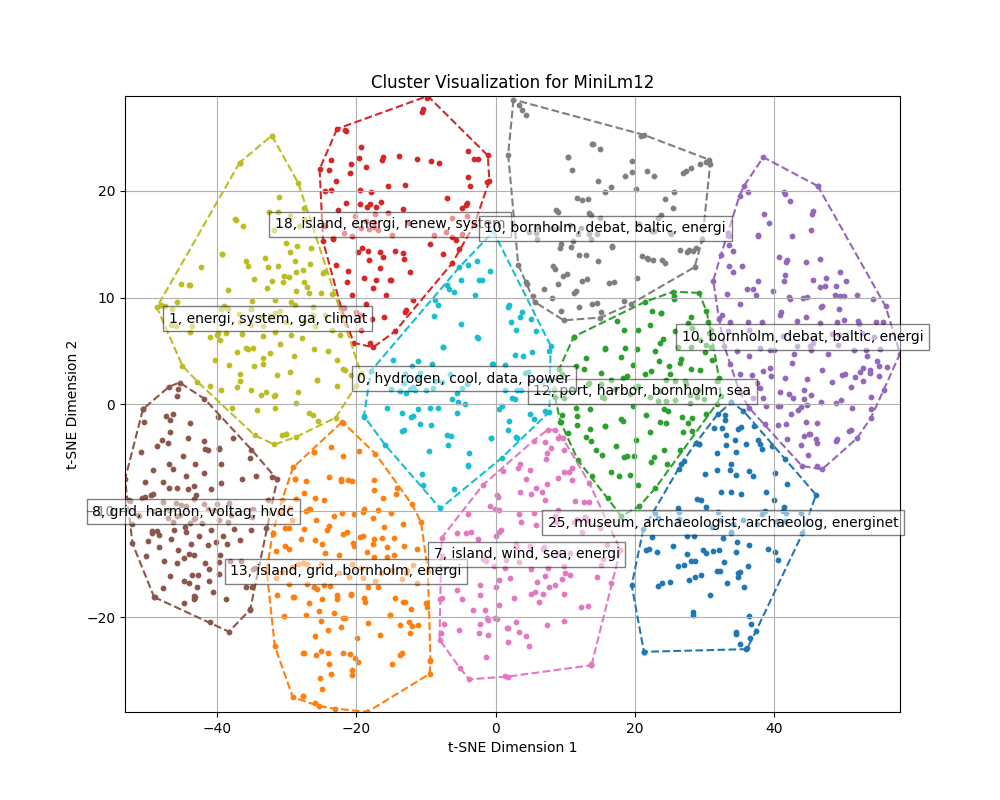
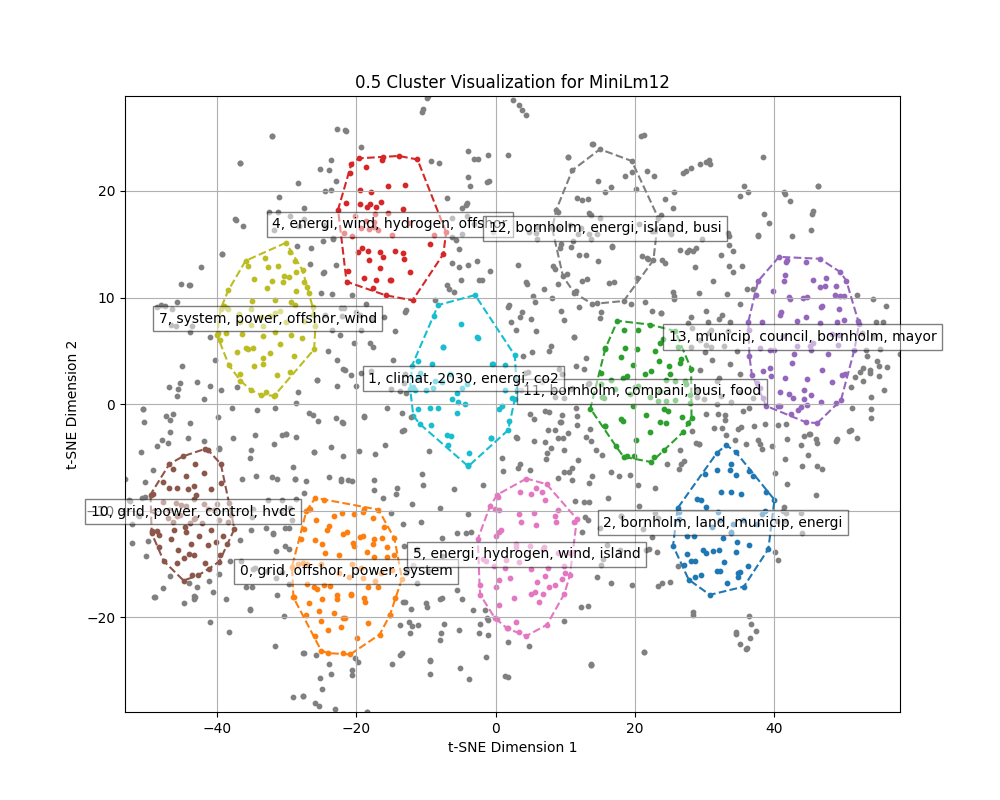
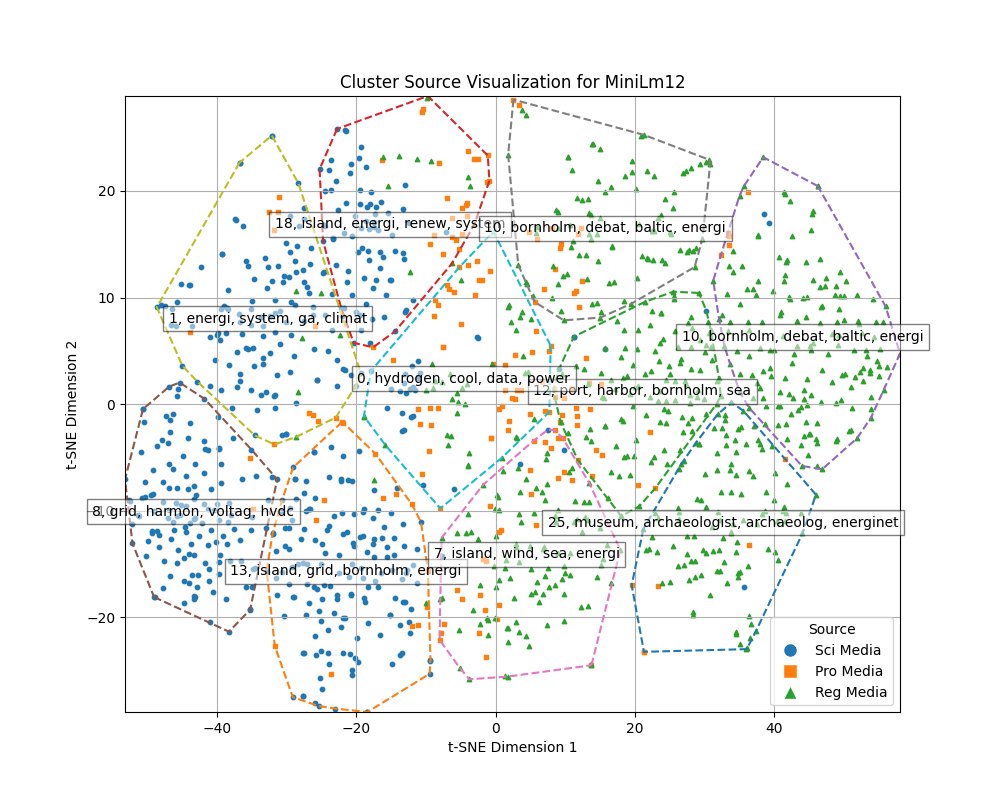
Dimensions from embeddings are reduced using TSNE and then K-means clustering is done to find clusters of documents.
At this stage we were interested in using TF-IDF only on the 50% of documents that were at the center of each cluster. This was not finished for the naming of clusters, but the visualization is made to explain the point.
Plots based on version 2 (old)
These are old plots from a previous version and are not a part of the final handin
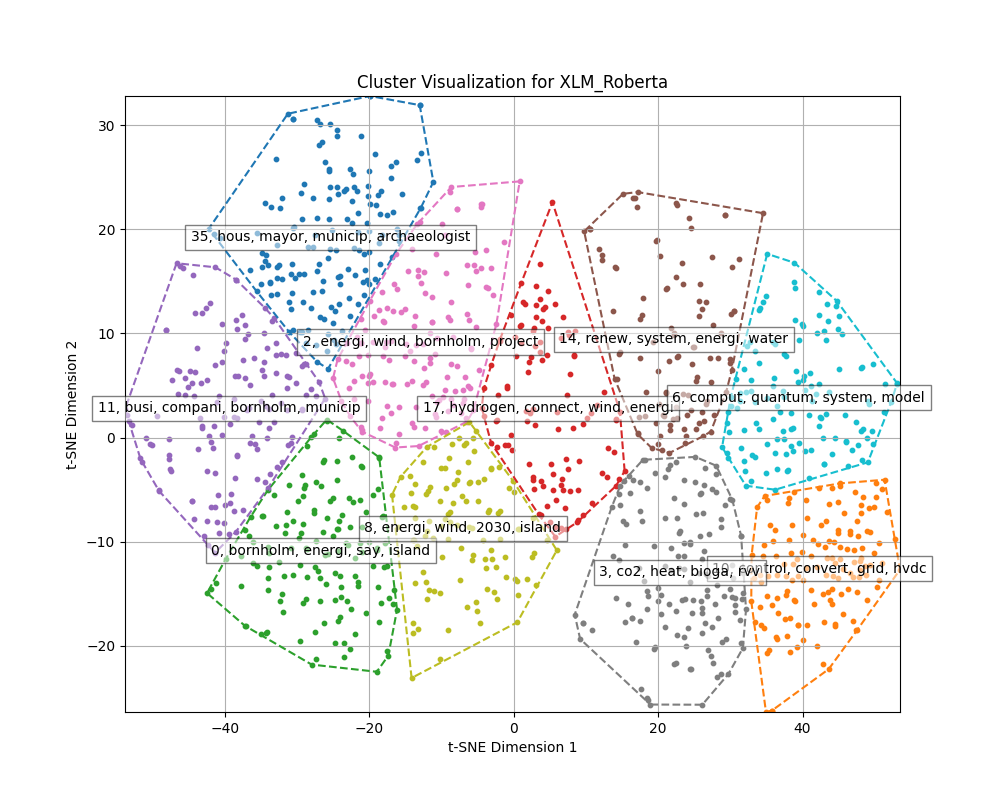
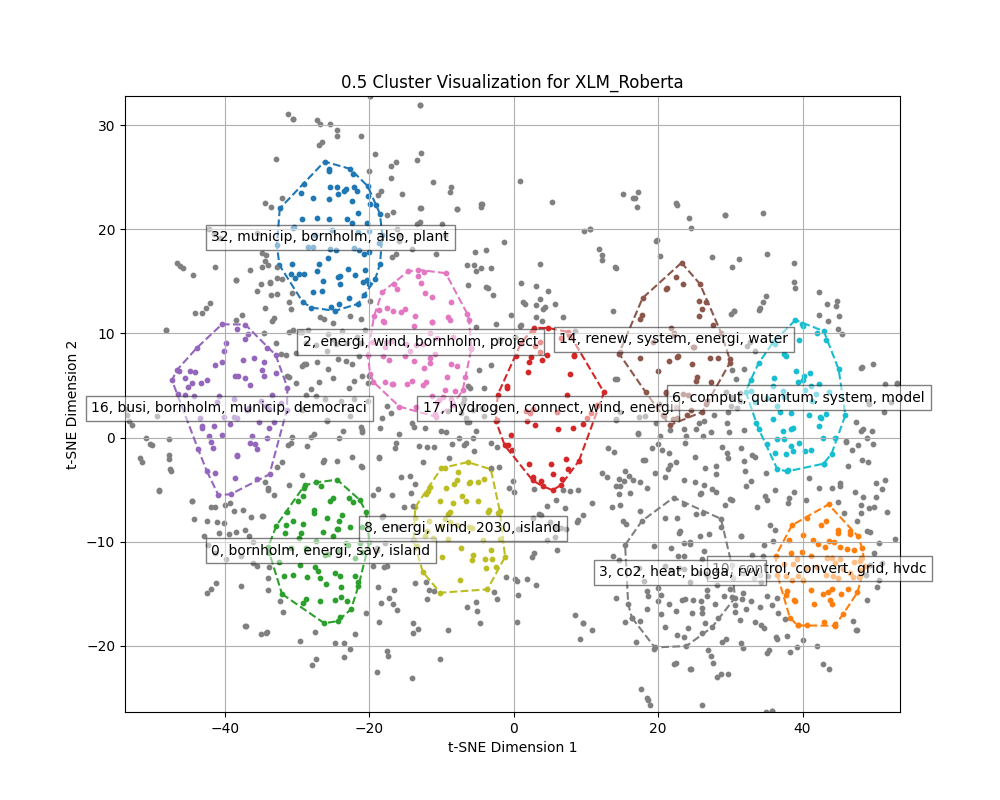
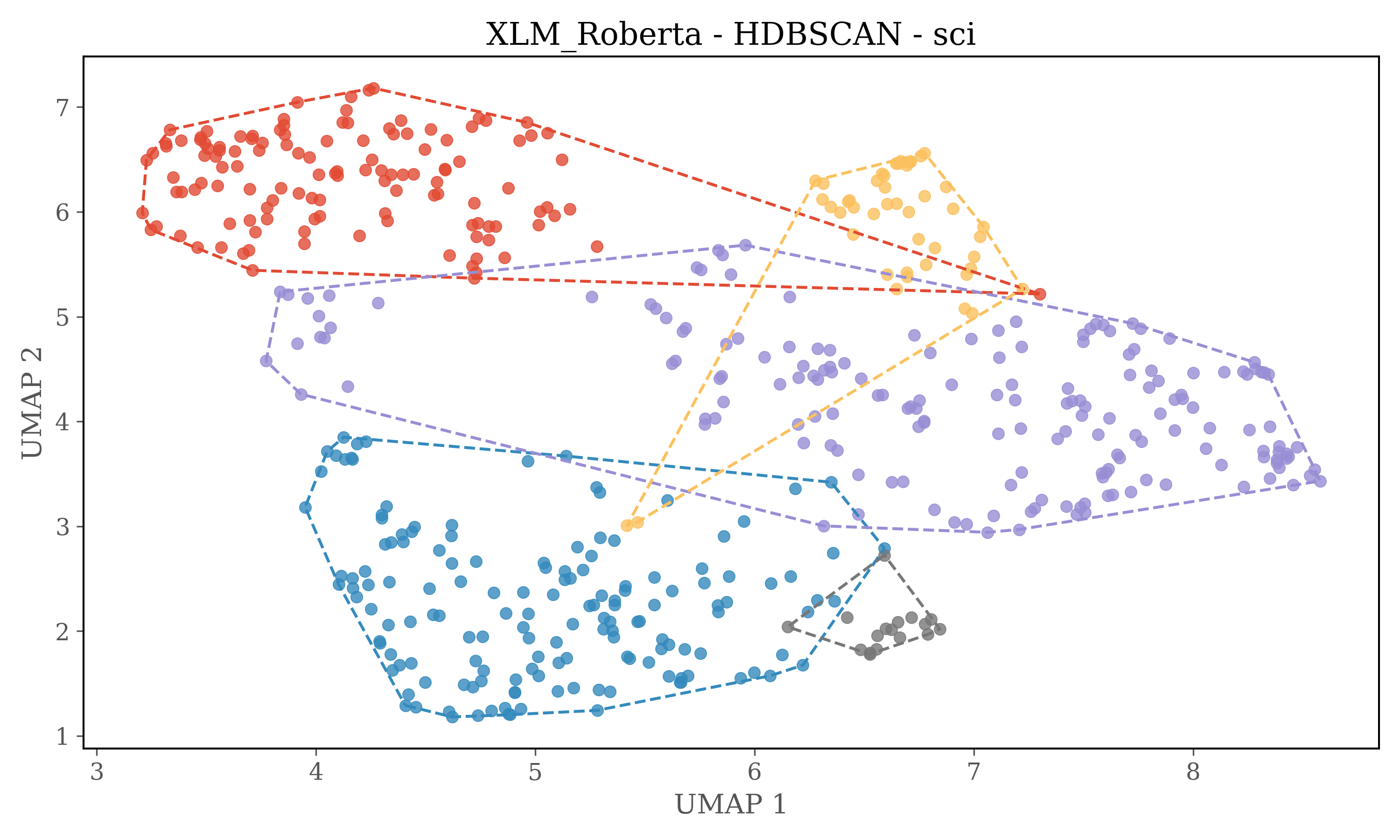
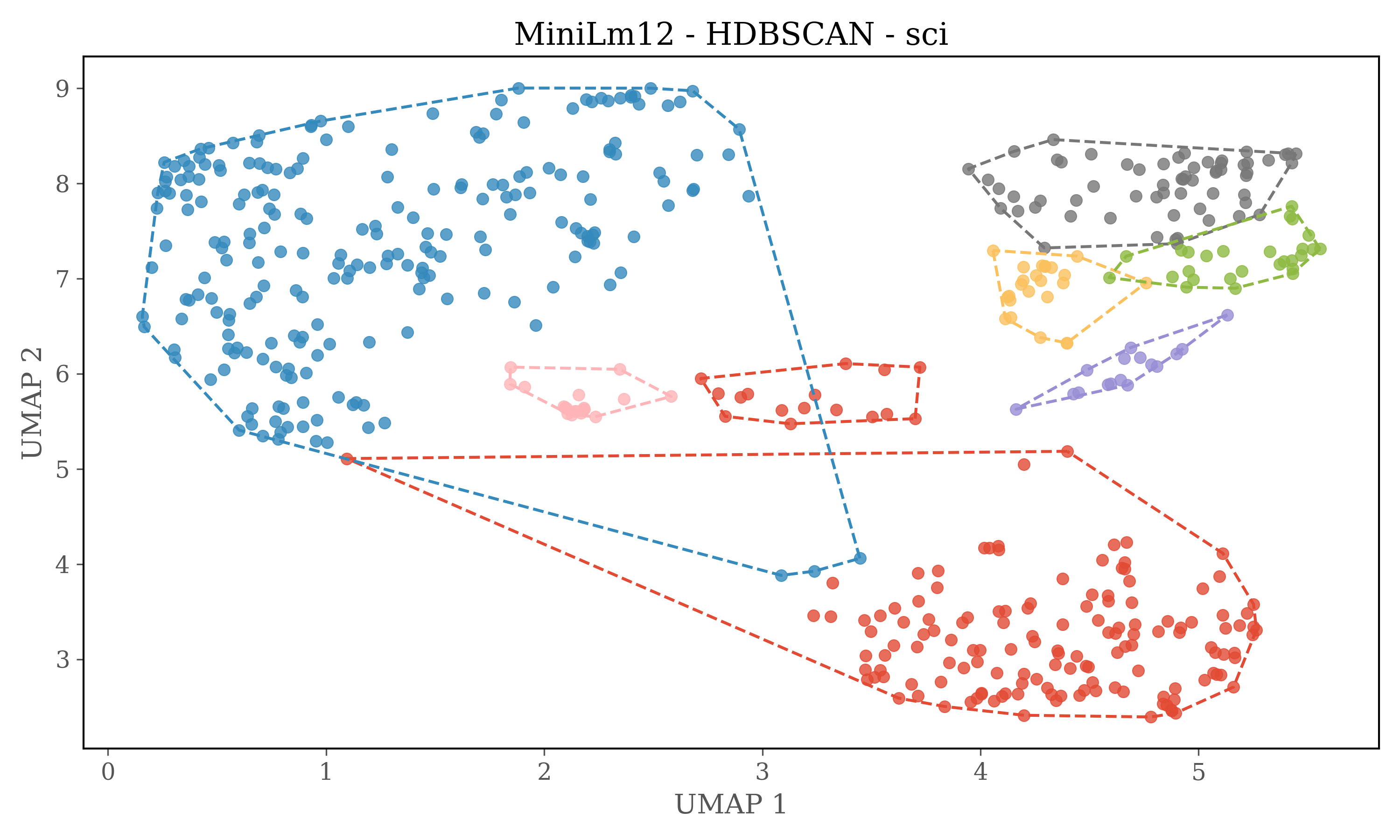
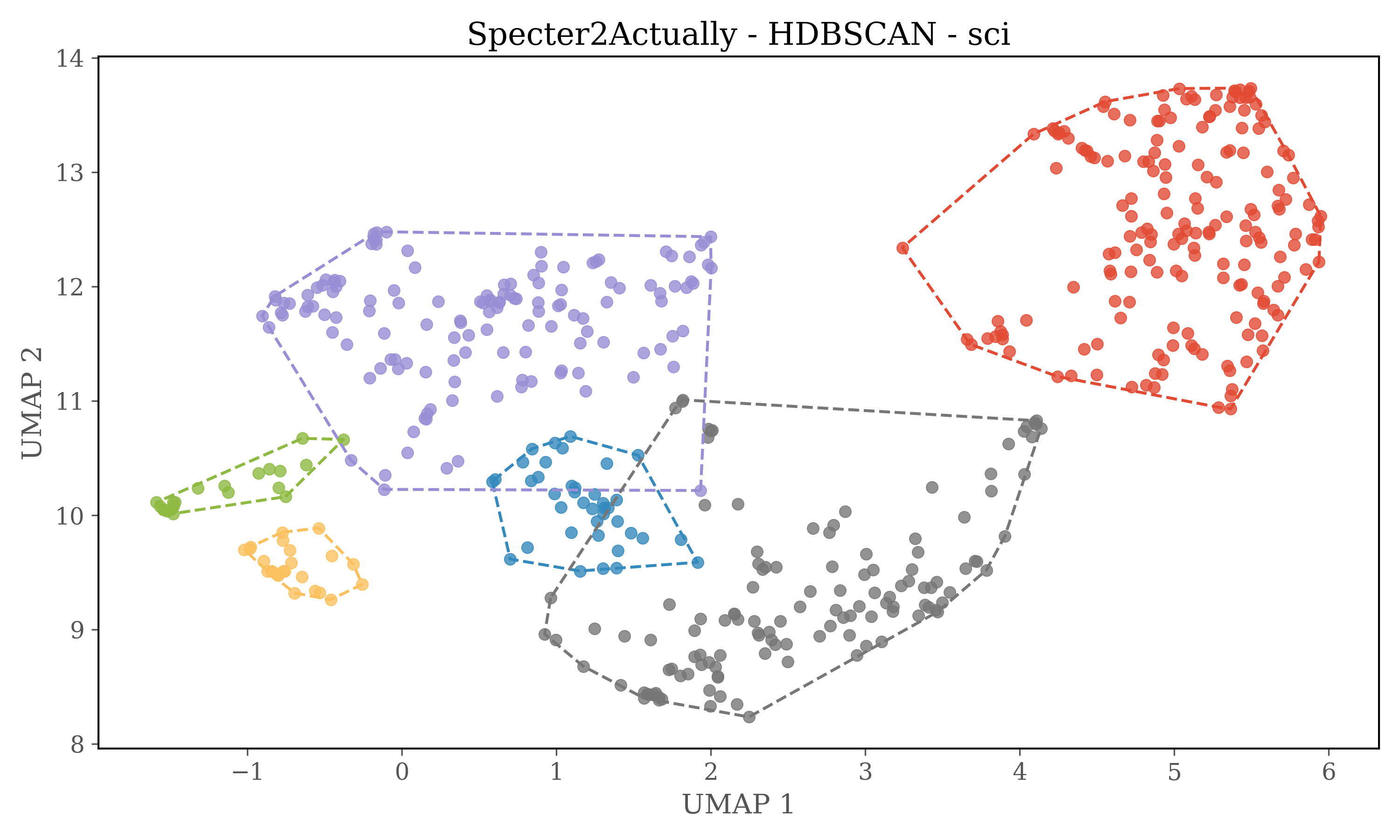
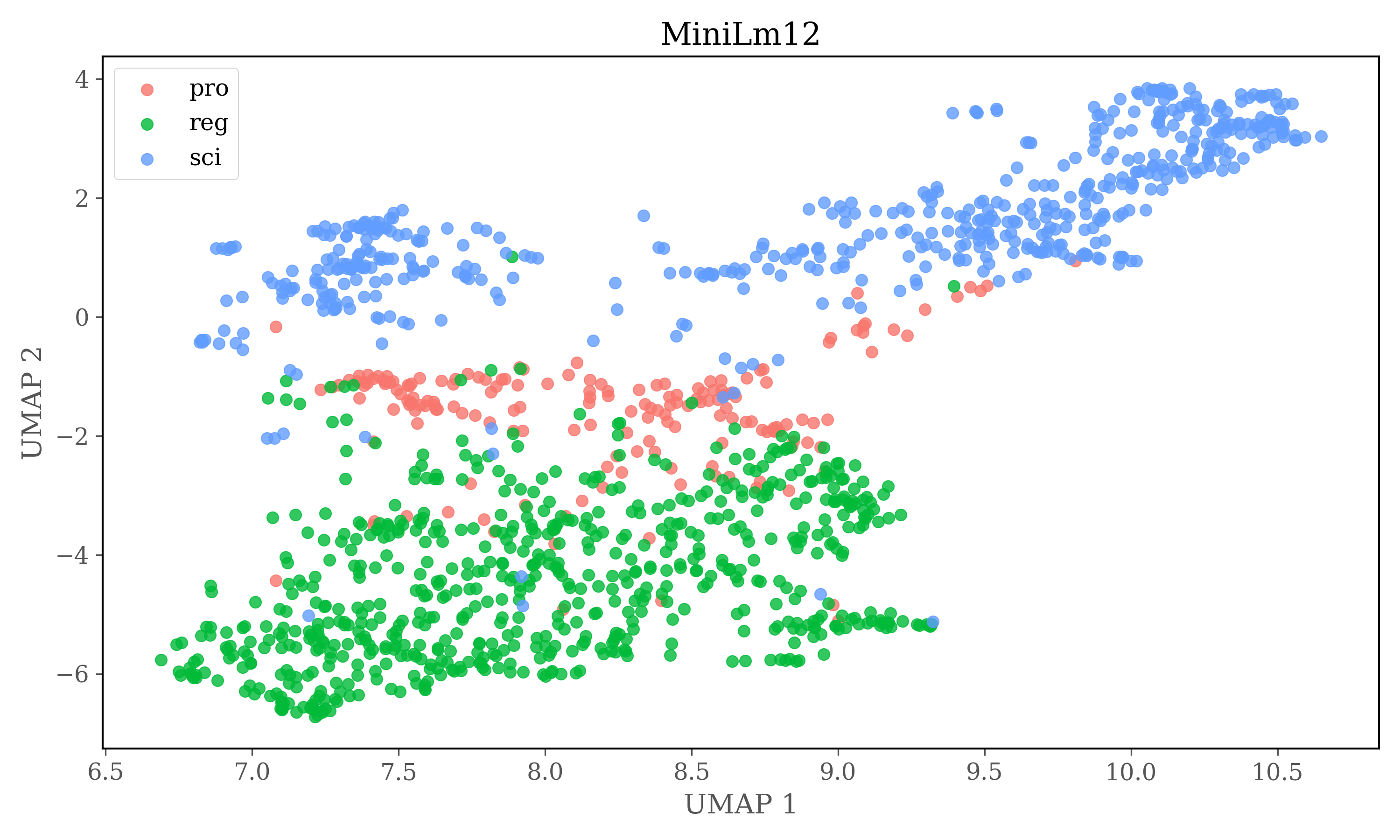
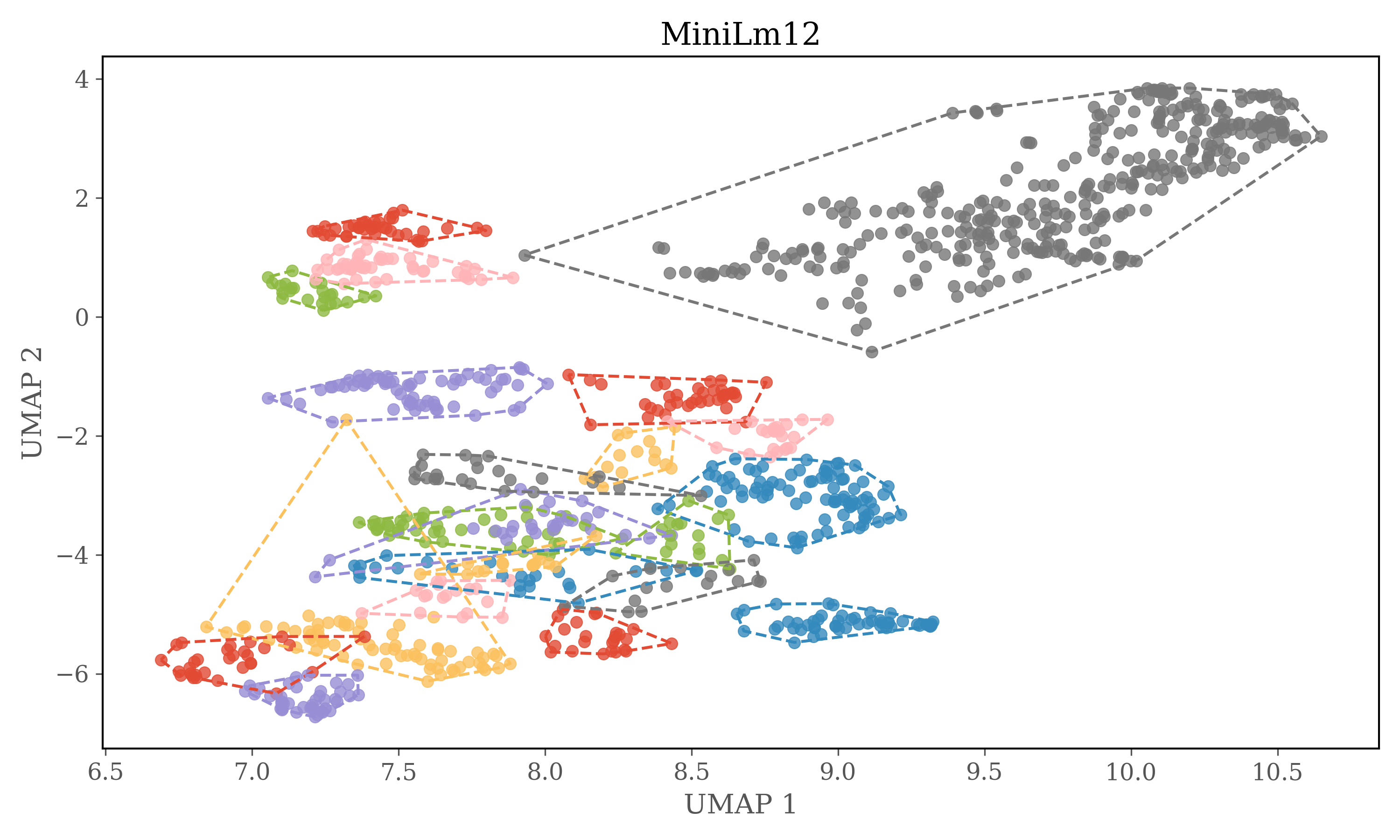
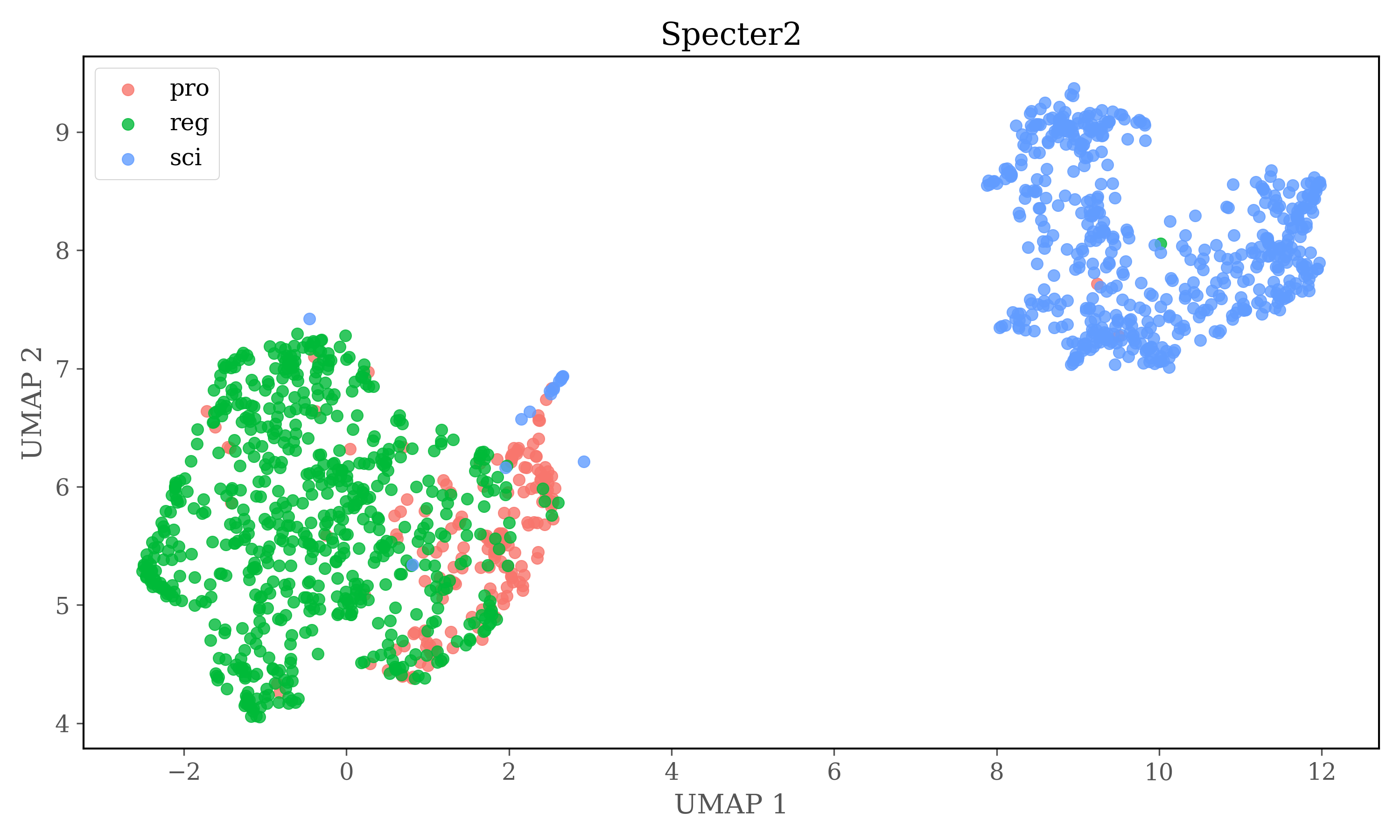
Dimensions of embeddings are reduced using UMAP, and then HDBSCAN is used for clustering.
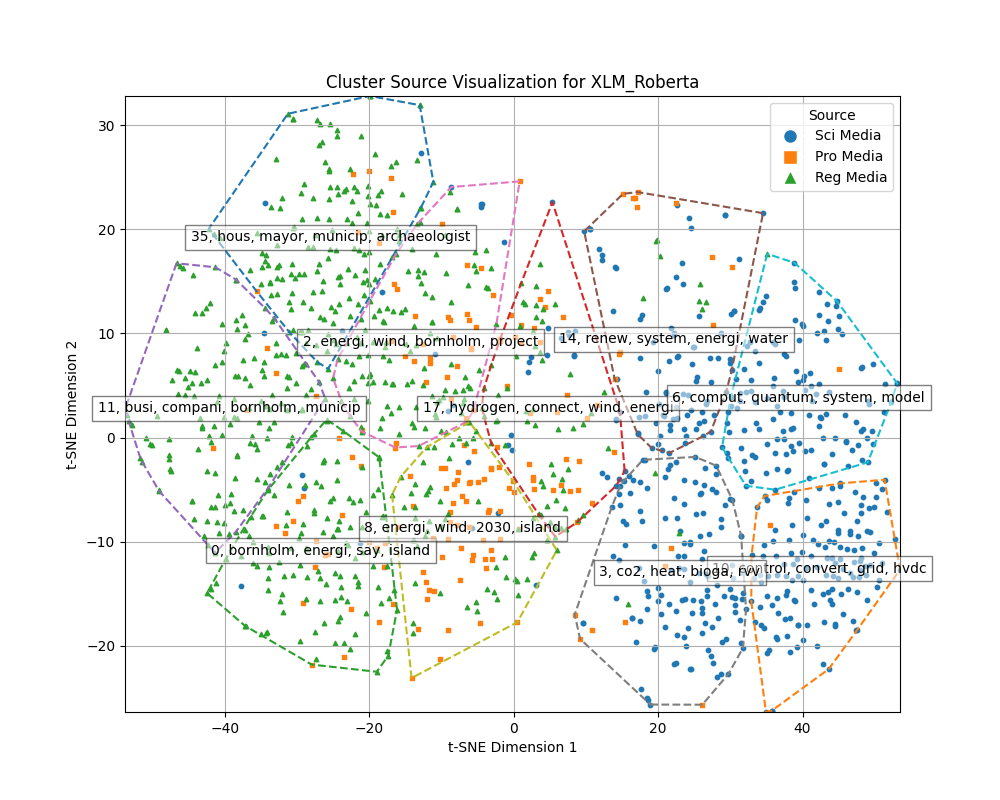
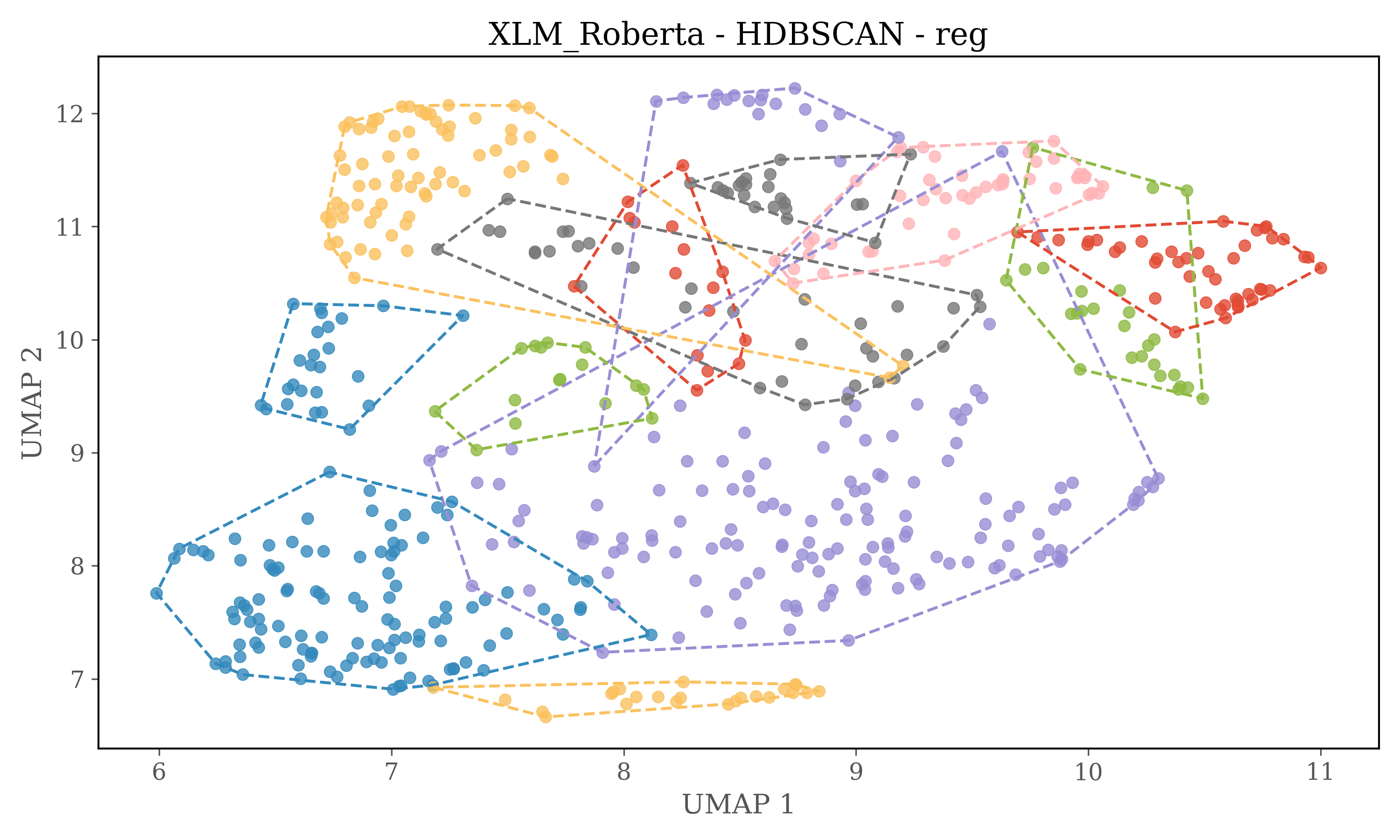
In version 2 each source is clustered seperately
HDBSCAN Clustering
HDBSCAN Clustering
HDBSCAN Clustering
Plots based on version 3
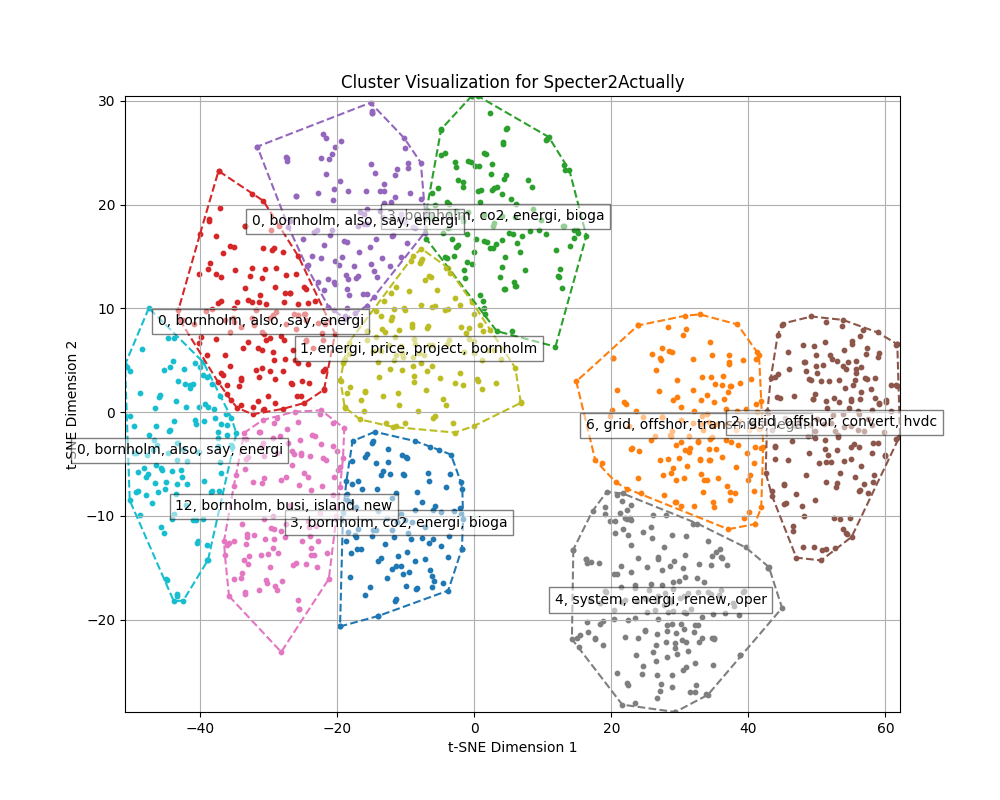
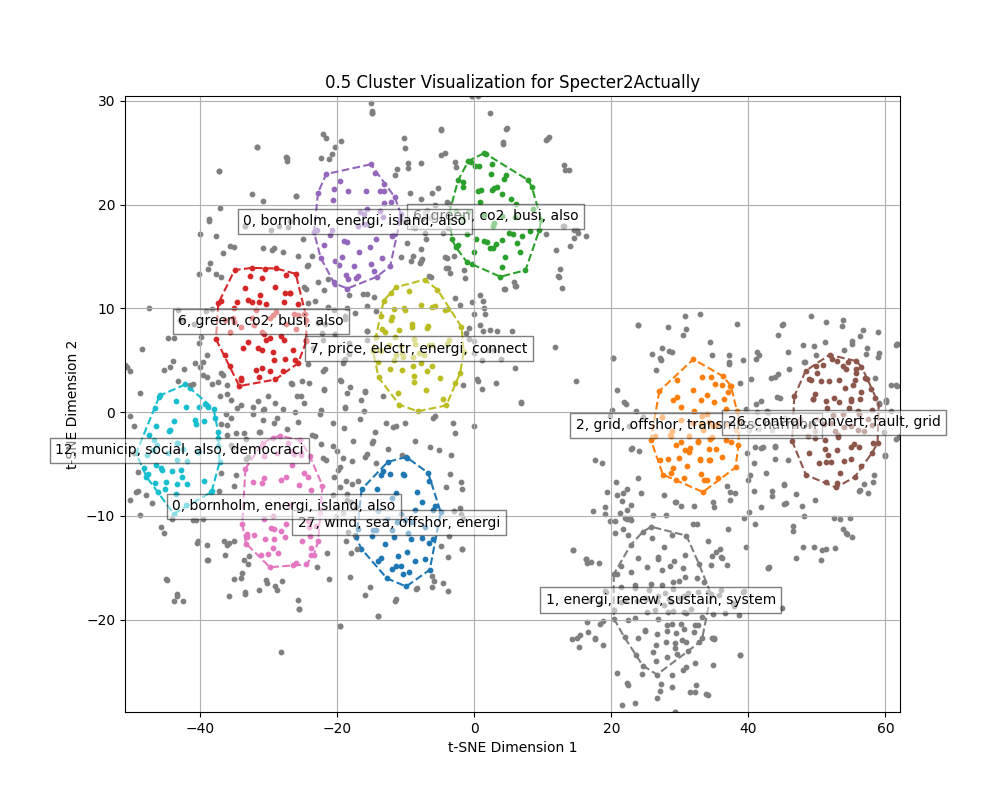
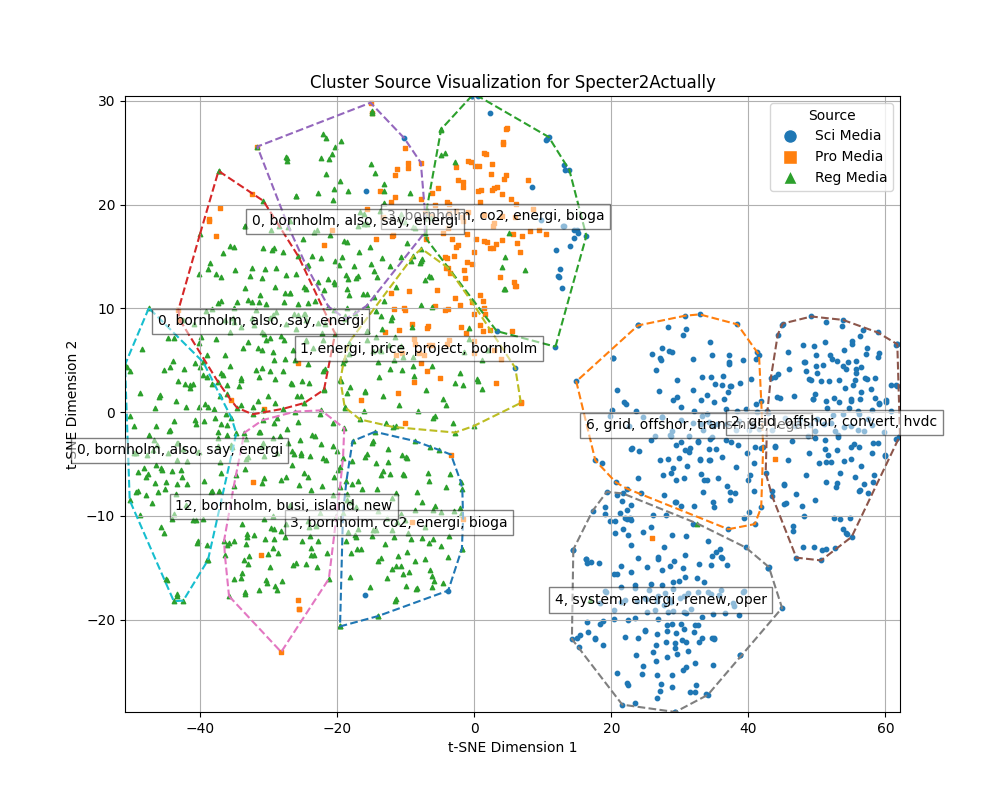
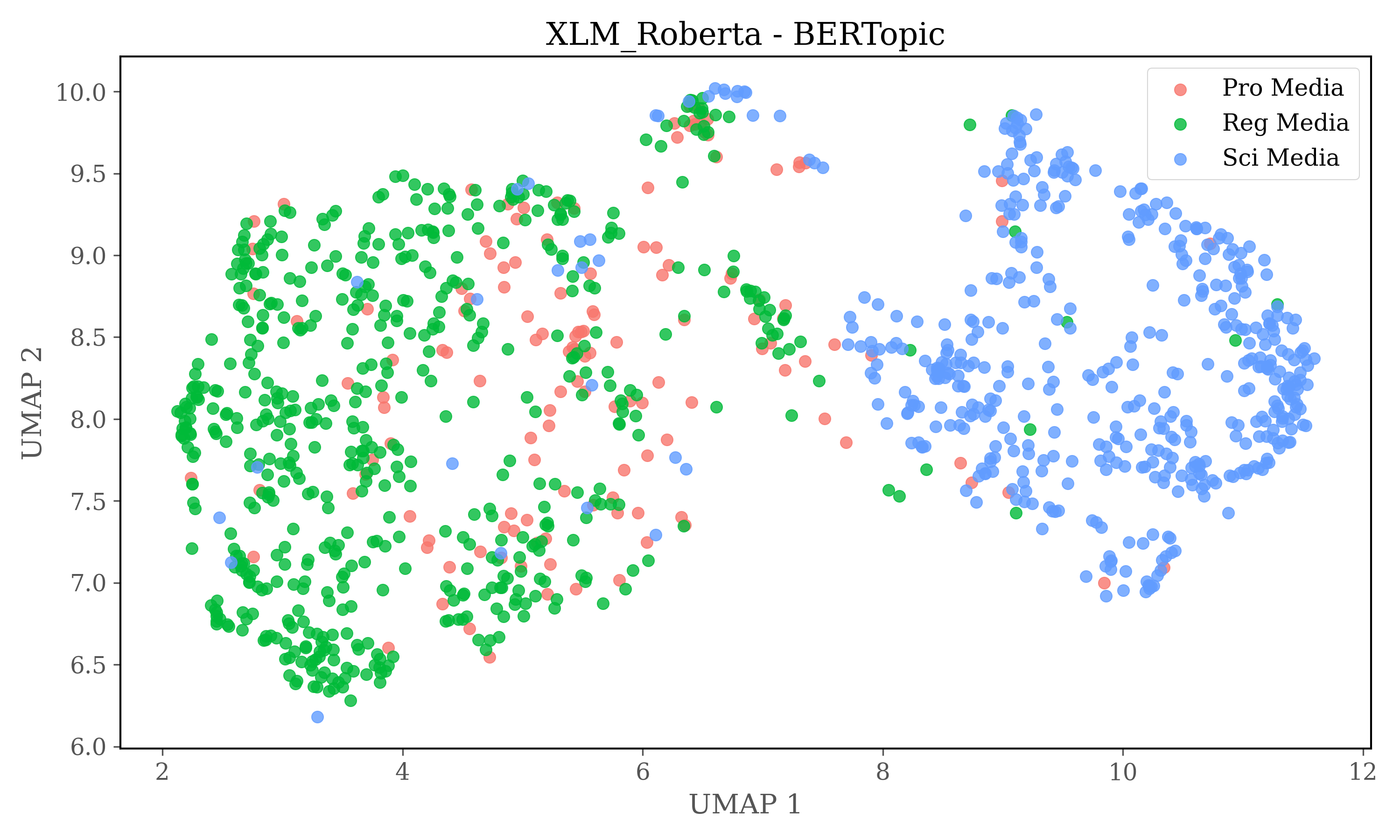
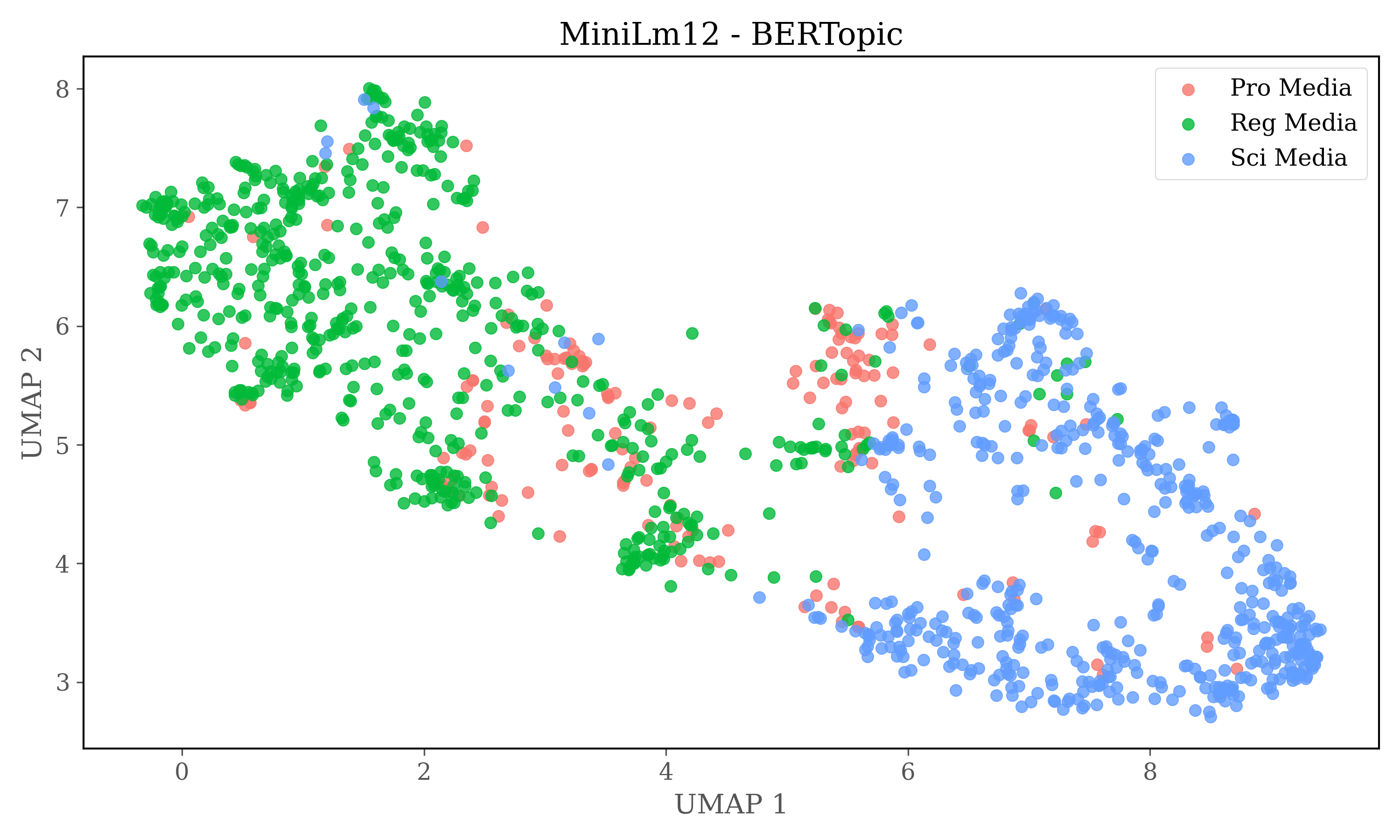
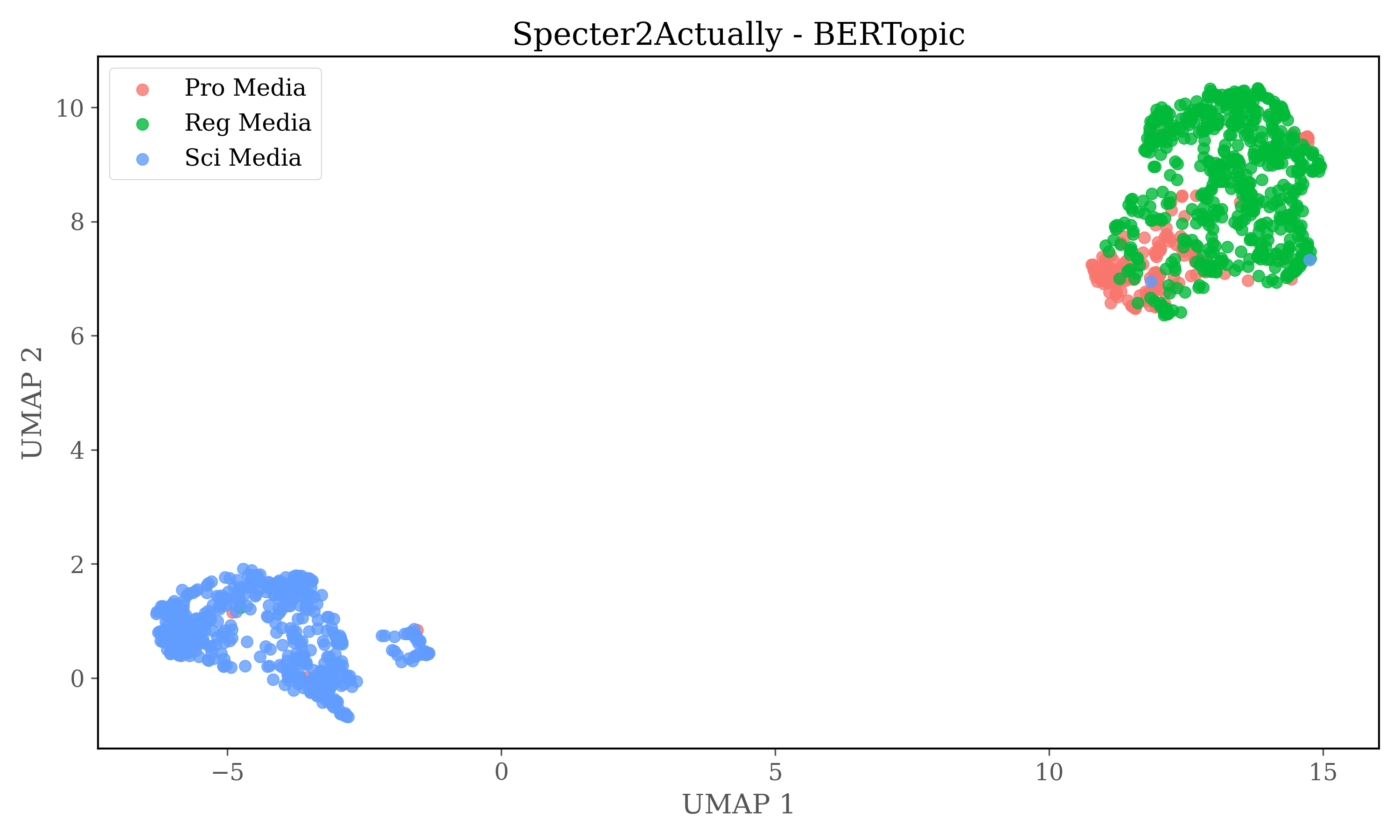
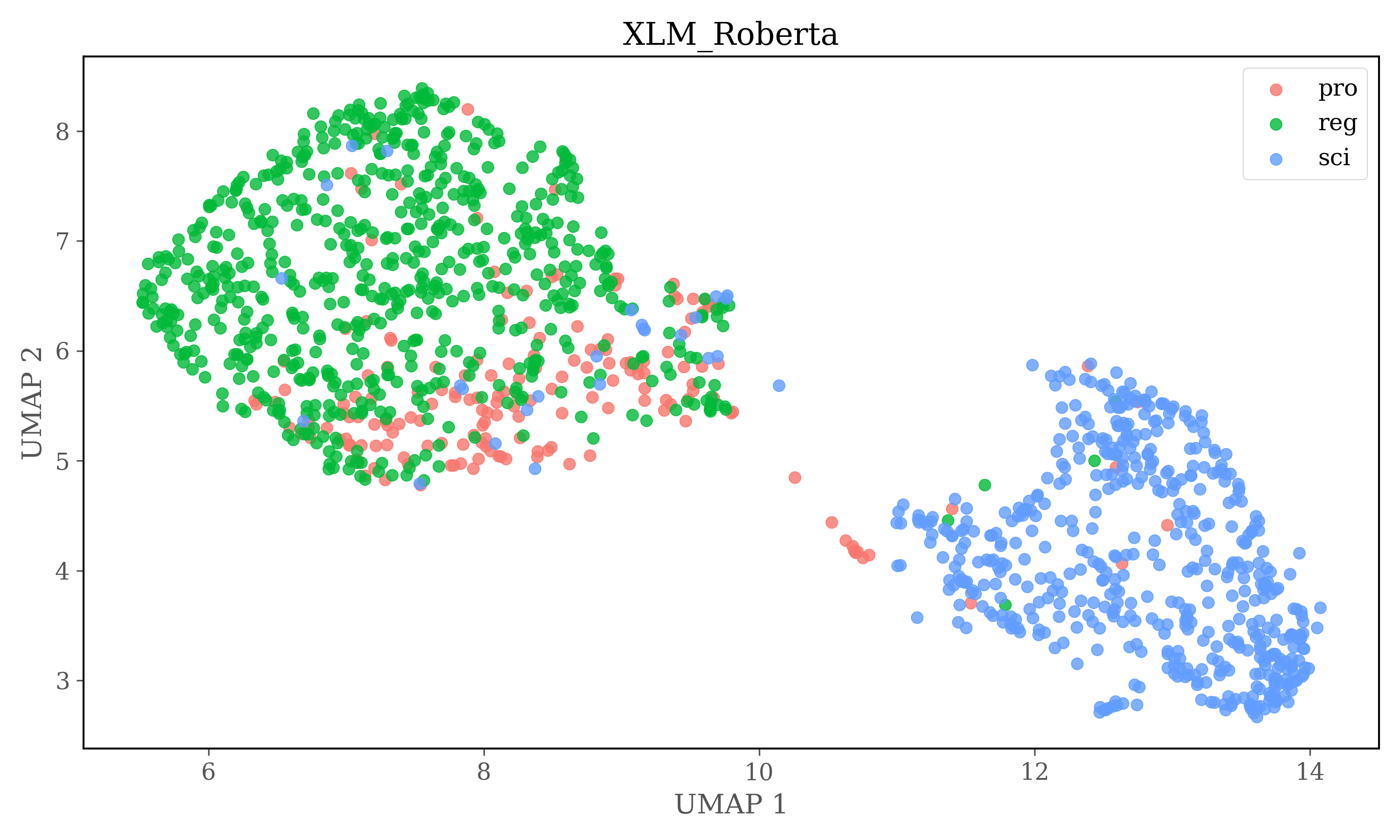
Cosine similarity clustering is conducted on the full dimensions of the embeddings, after the clustering UMAP is used to reduce dimensions to two for plots. Therefore no conclusions can be drawn from the plots alone, but it gives insights into the source distribution in clusters
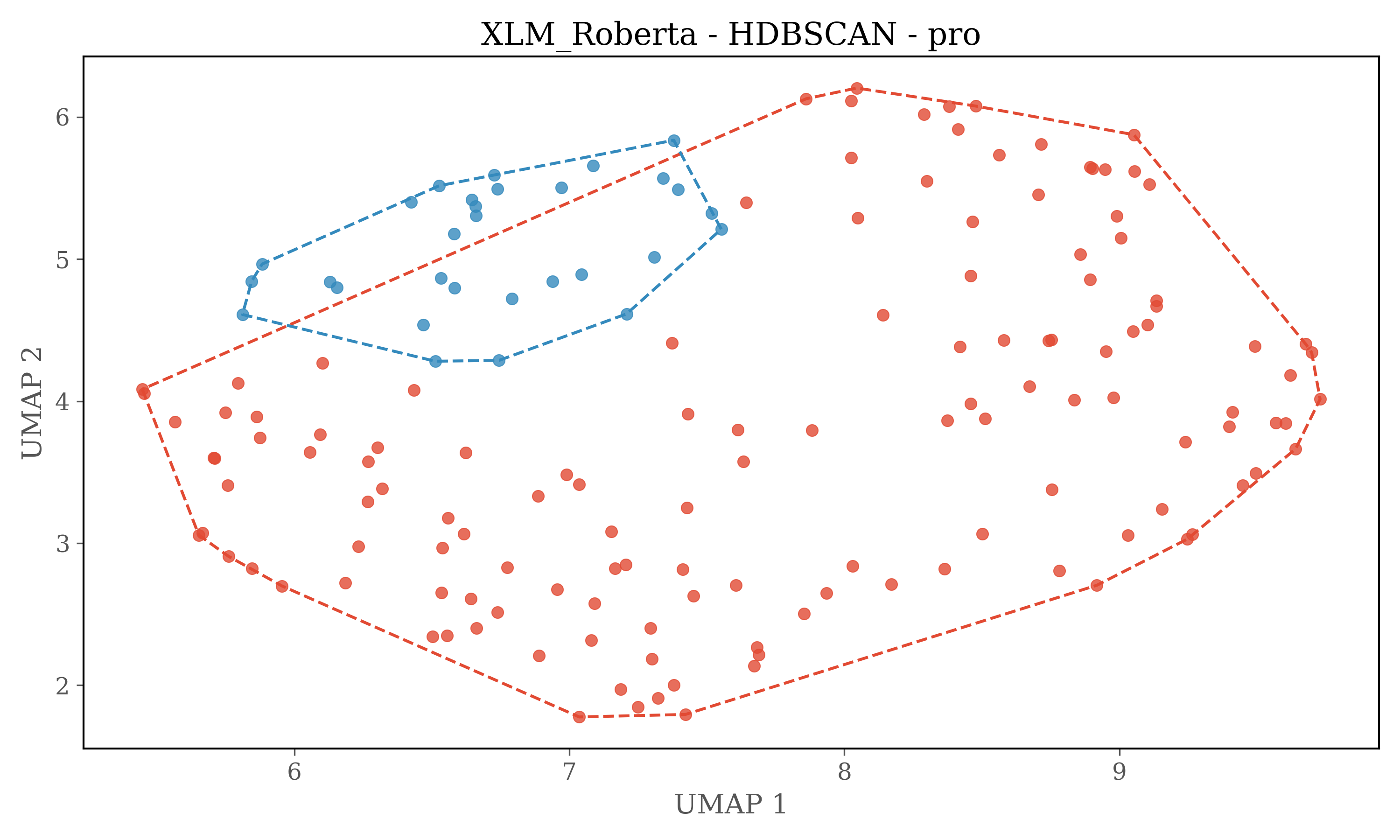
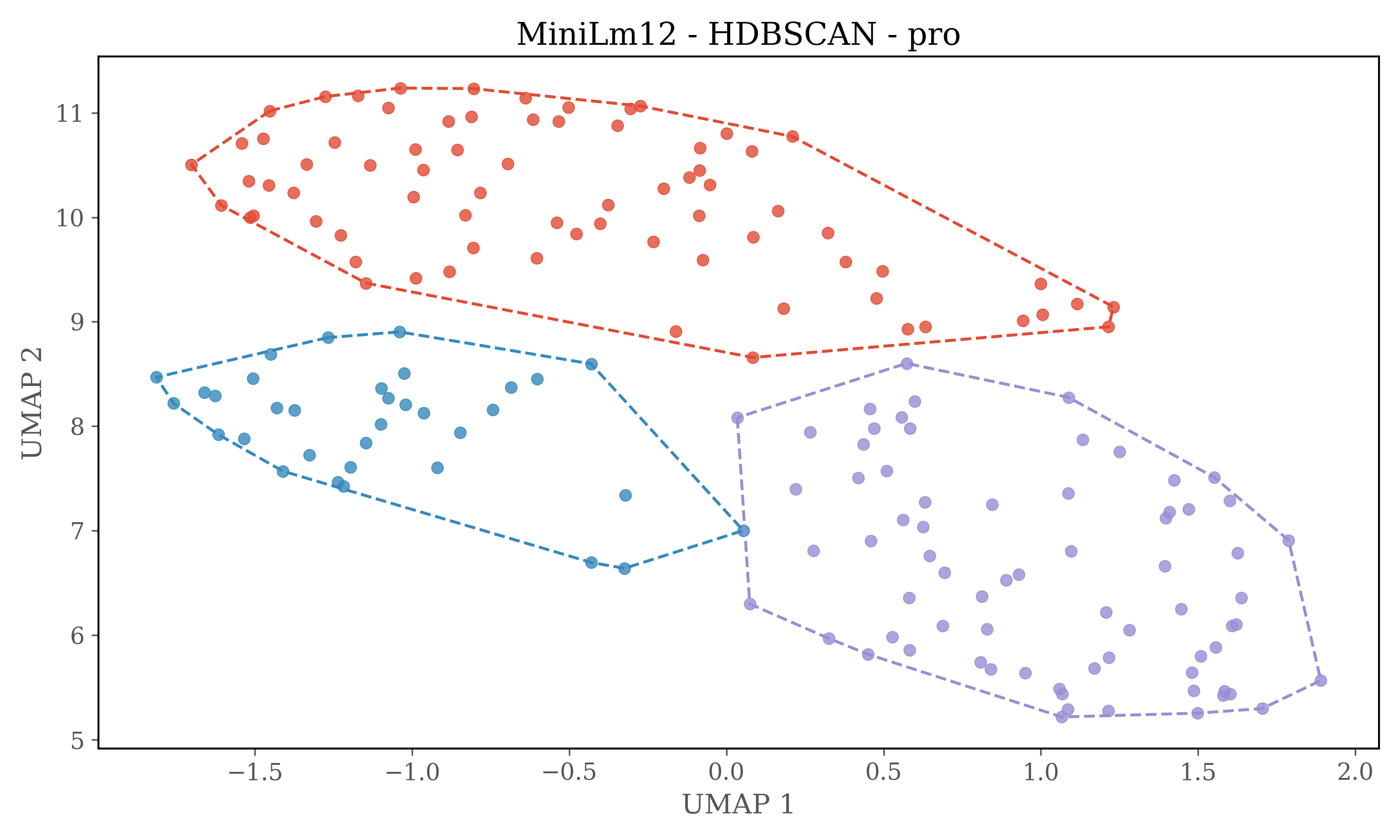
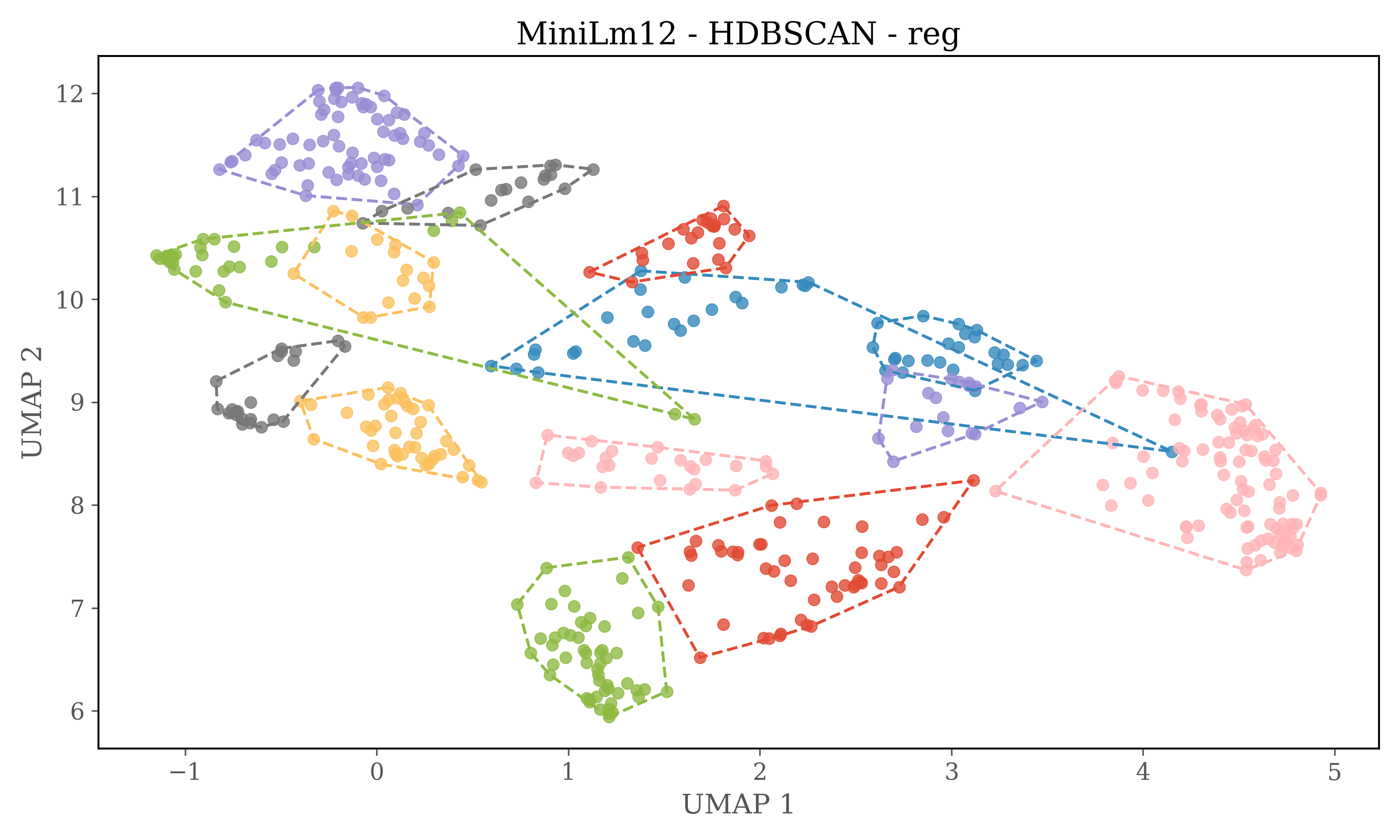
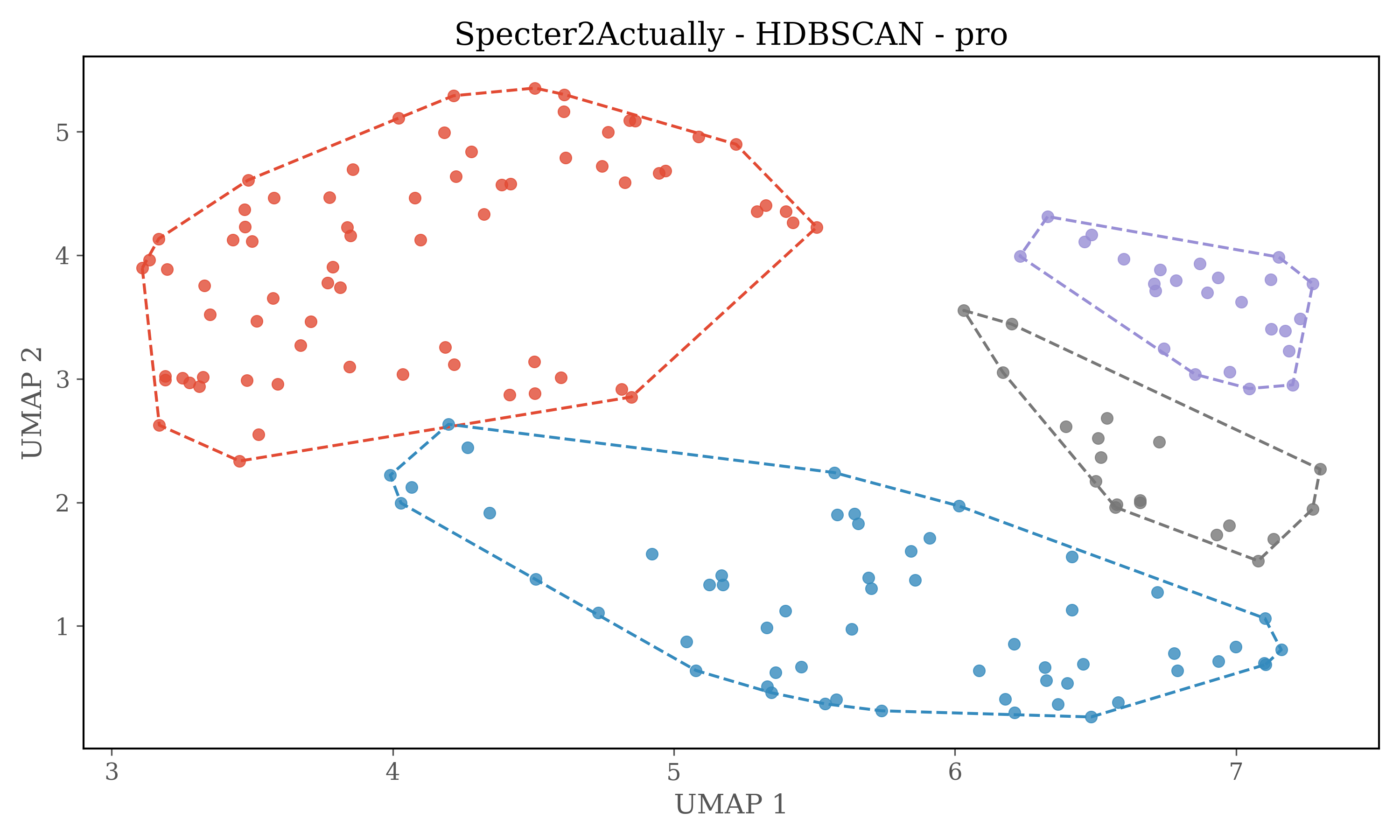
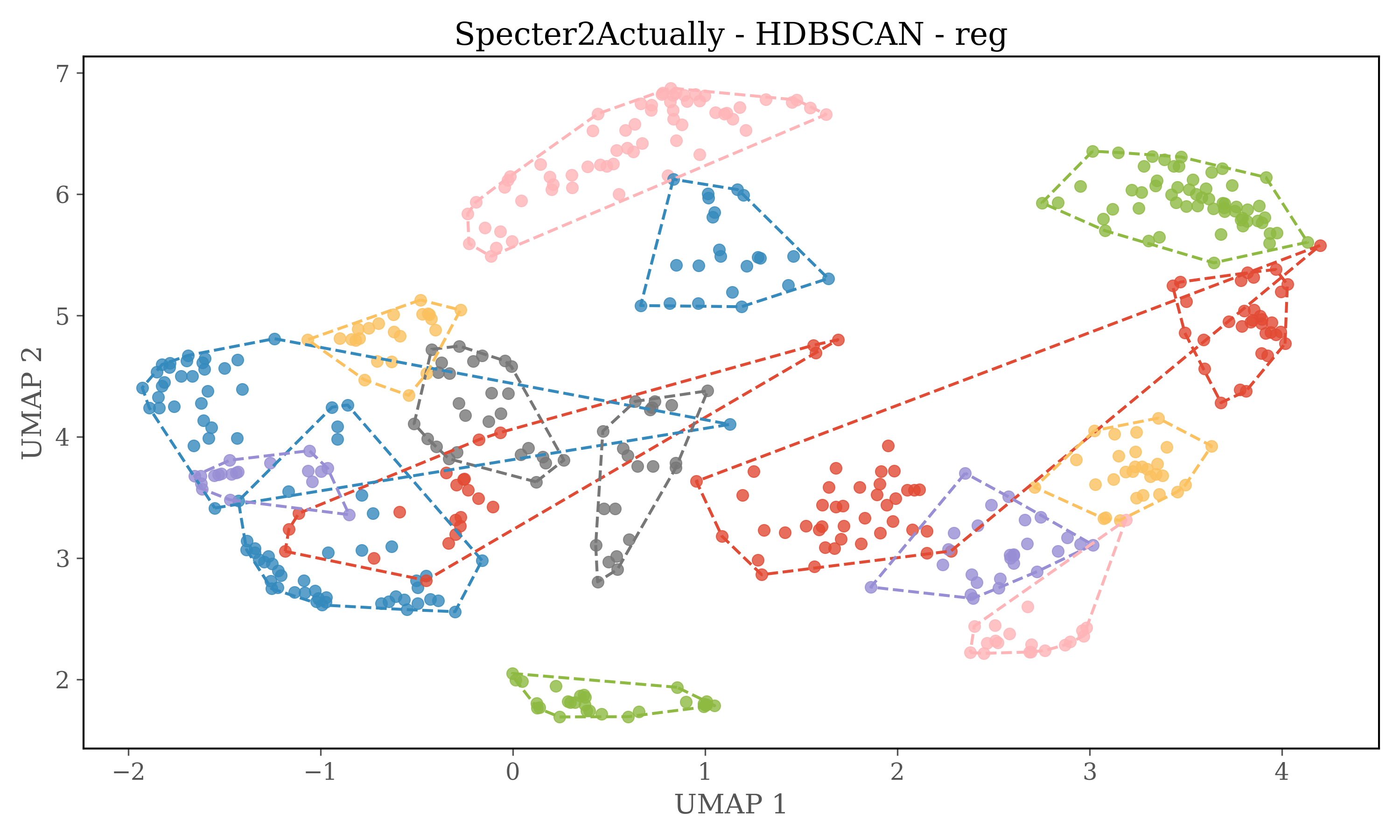
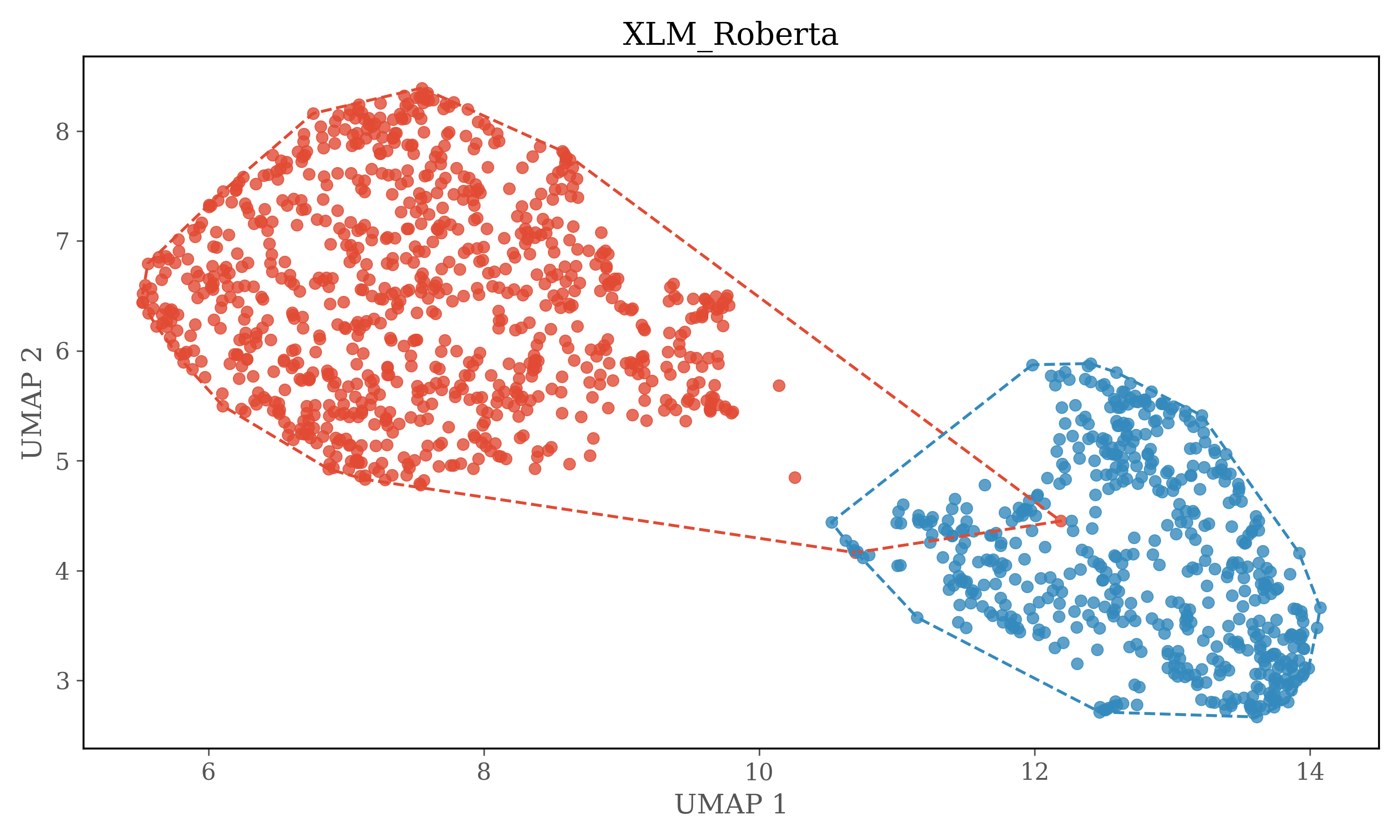
For HDBSCAN clustering plots dimensions of embeddings are reduced to 5 using UMAP, and then HDBSCAN is used for clustering.
Cosine similarity Clustering
HDBSCAN Clustering
Cosine similarity Clustering
HDBSCAN Clustering
Cosine similarity Clustering
HDBSCAN Clustering
About
We are three friends from DTU collaborating together on this bachelor project supervised by Anders Kristian Munk